让大模型不再过度思考!上海AI Lab后训练新范式重塑CoT,推理又快又好
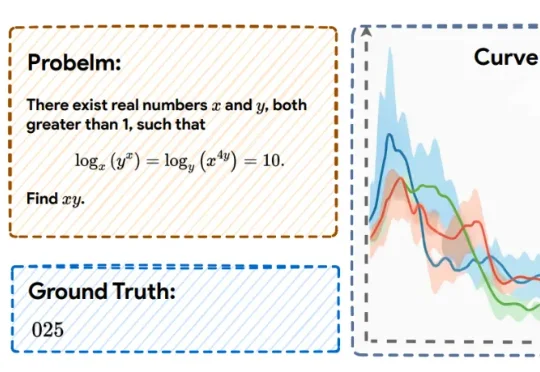
让大模型不再过度思考!上海AI Lab后训练新范式重塑CoT,推理又快又好近日,上海人工智能实验室的研究团队提出了一种全新的后训练范式——RePro(Rectifying Process-level Reward)。这篇论文将推理的过程视为模型内部状态的优化过程,从而对如何重塑大模型的CoT提供了一个全新视角:
来自主题: AI技术研报
8627 点击 2025-12-21 12:35
 搜索
搜索
近日,上海人工智能实验室的研究团队提出了一种全新的后训练范式——RePro(Rectifying Process-level Reward)。这篇论文将推理的过程视为模型内部状态的优化过程,从而对如何重塑大模型的CoT提供了一个全新视角:

AI不应是巨头游戏,模型也不是越大越聪明。近日,「Transformer八子」中的Ashish Vaswani和Parmar共同推出了一个8B的开源小模型,剑指Scaling Law软肋,为轻量化、开放式AI探索了新方向。
随着大型语言模型在各类任务中展现出卓越的生成与推理能力,如何将模型输出精确地追溯到其内部计算过程,已成为 AI 可解释性研究的重要方向。然而,现有方法往往计算代价高昂、难以揭示中间层的信息流动;同时,不同层面的归因(如 token、模型组件或表示子空间)通常依赖各自独立的特定方法,缺乏统一且高效的分析框架。
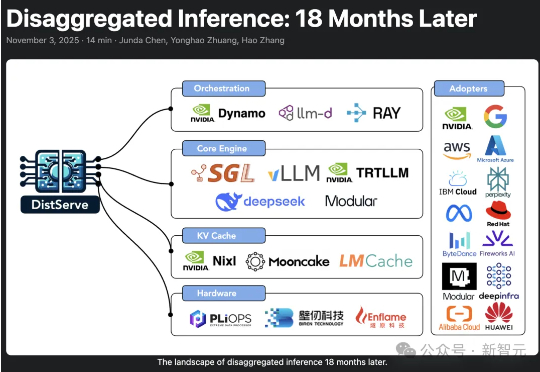
2024年,加州大学圣地亚哥分校「Hao AI Lab」提出了DistServe的解耦推理理念,短短一年多时间,迅速从实验室概念成长为行业标准,被NVIDIA、vLLM等主流大模型推理框架采用,预示着AI正迈向「模块化智能」的新时代。
本文来自于香港中文大学 MMLab 和 vivo AI Lab,其中论文第一作者肖涵,主要研究方向为多模态大模型和智能体学习,合作作者王国志,研究方向为多模态大模型和 Agent 强化学习。项目 le

近日,上海人工智能实验室针对该难题提出全新范式 SDAR (Synergistic Diffusion-AutoRegression)。该方法通过「训练-推理解耦」的巧妙设计,无缝融合了 AR 模型的高性能与扩散模型的并行推理优势,能以极低成本将任意 AR 模型「改造」为并行解码模型。

科技行业全球10万大裁员,连10年老将田渊栋都被Meta裁掉了!昨天,南洋理工大学的副教授Boyang Li吊足了大家的胃口:Meta FAIR最近的事件很抓马,但工业研究为什么这么难?我想知道大家愿不愿意听一下我的观点。
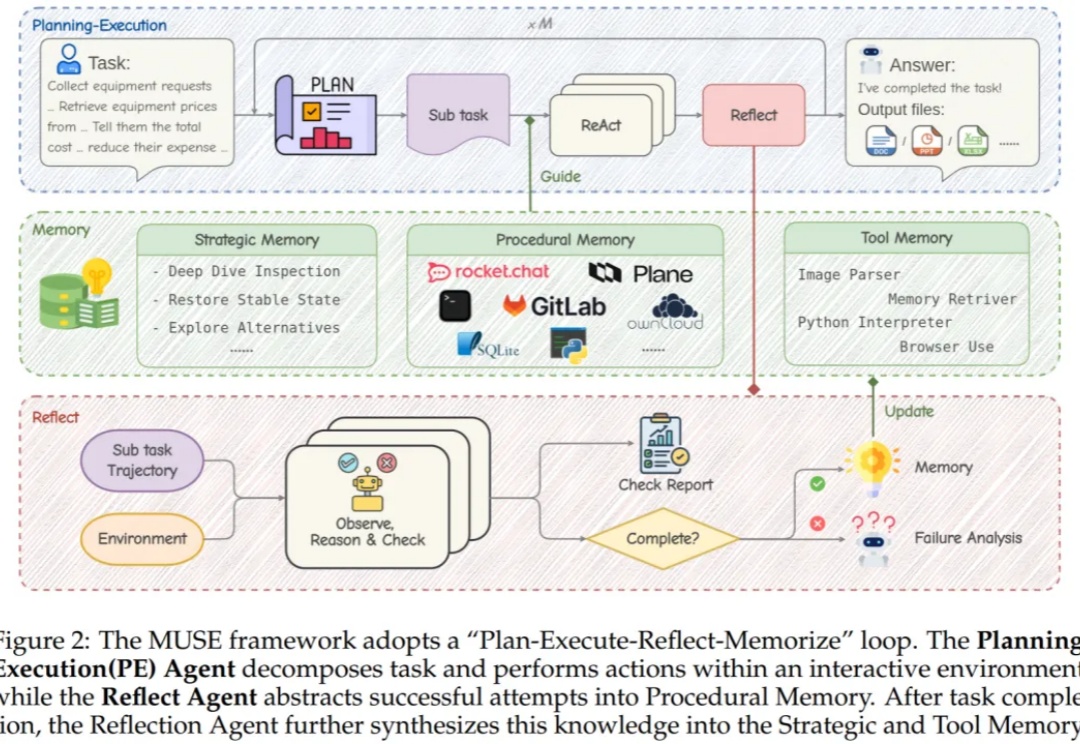
在人工智能的广阔世界里,我们早已习惯了LLM智能体在各种任务中大放异彩。但有没有那么一瞬间,你觉得这些AI“牛马”还是缺了点什么?
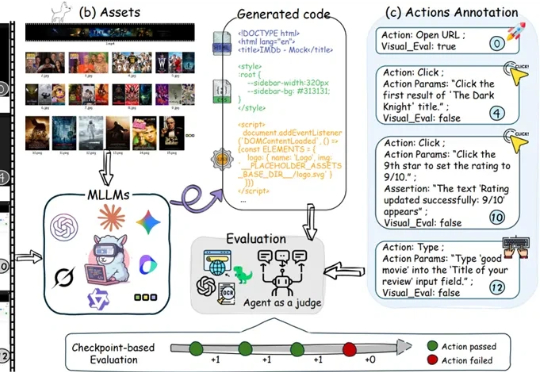
多模态大模型在根据静态截图生成网页代码(Image-to-Code)方面已展现出不俗能力,这让许多人对AI自动化前端开发充满期待。
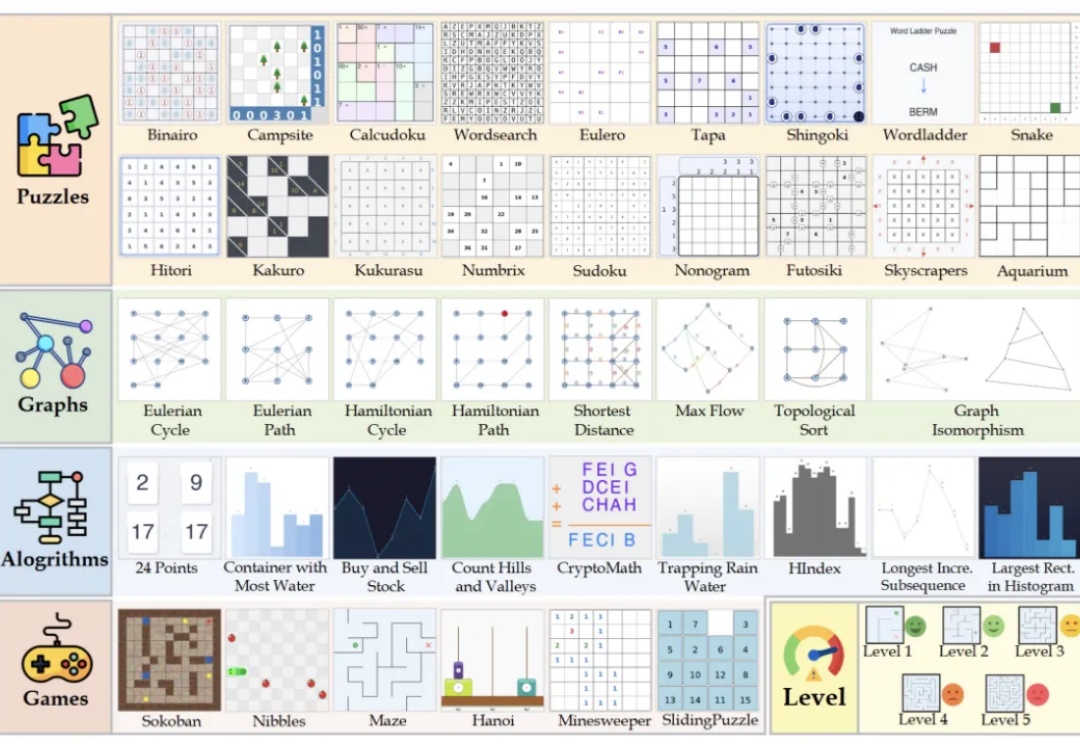
多模态大模型表现越来越惊艳,但人们也时常困于它的“耿直”。